I started a fork of the Whitney’s opendata Github repository for my project files. Not sure if forking or branching is a better approach for keeping my contributions to the project, but I can always change the structure later:
https://github.com/MollieEcheverria/opendata
I’m currently trying to re-model how the Whitney’s linked data is structured. Joshua’s structure uses Schema.org, but I would like to attempt to model the existing data onto CIDOC if possible, in keeping with what the British Museum has done with their linked data, as well as the Carnegie Museum’s model.
I’m starting by trying to create a data model using Draw.io. This is proving a little confusing thus far: https://drive.google.com/file/d/0B2gZKtQxkfUhX19FdXlDUEp2b2c/view?usp=sharing
Additionally, I am trying to convert a sample British Museum object record (http://collection.britishmuseum.org/id/object/EOC3130) from JSON to CSV using Python, in order to try to reverse engineer converting CSV field data to CIDOC-structured JSON. My script attempts(s) are in my Github repository.
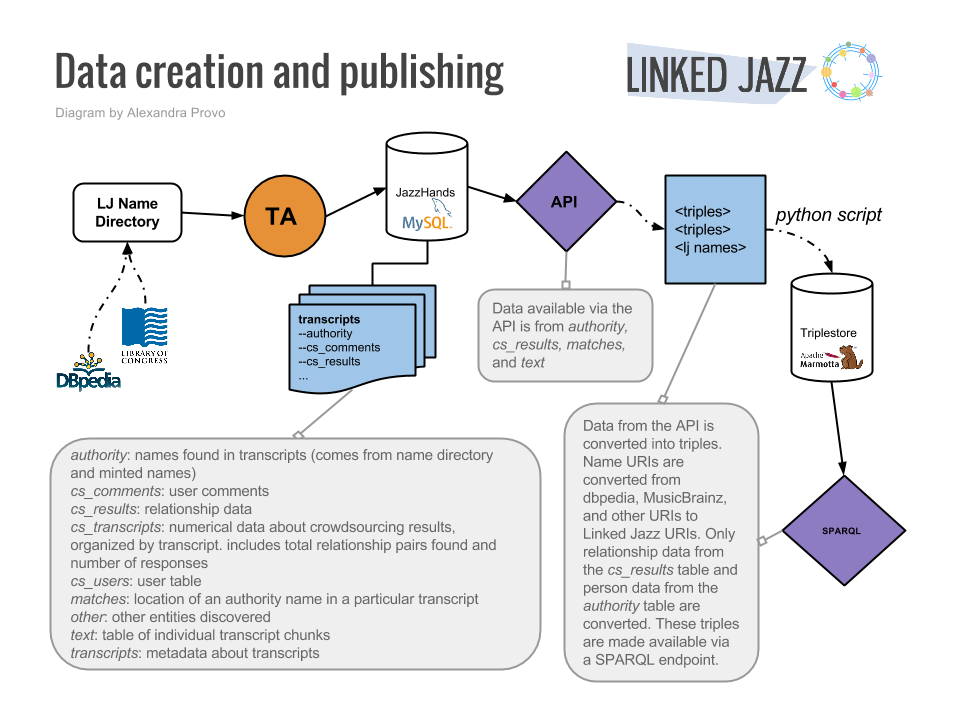
Database-wise, since SQL can be used to output JSON, I’m planning to keep using and appending Joshua’s MySQL database for now. If and when a triple-store is implemented at the Whitney, JSON-LD/.nt files would need to be fed into it, so the MySQL database would serve as the source for generating these files. This seems to be how Linked Jazz at Pratt generated their triples as well (or at least how they stored the names from the transcripts they analyzed : https://linkedjazz.org/data-productionworkflow-draft/)