Linked Data in a Relational Database
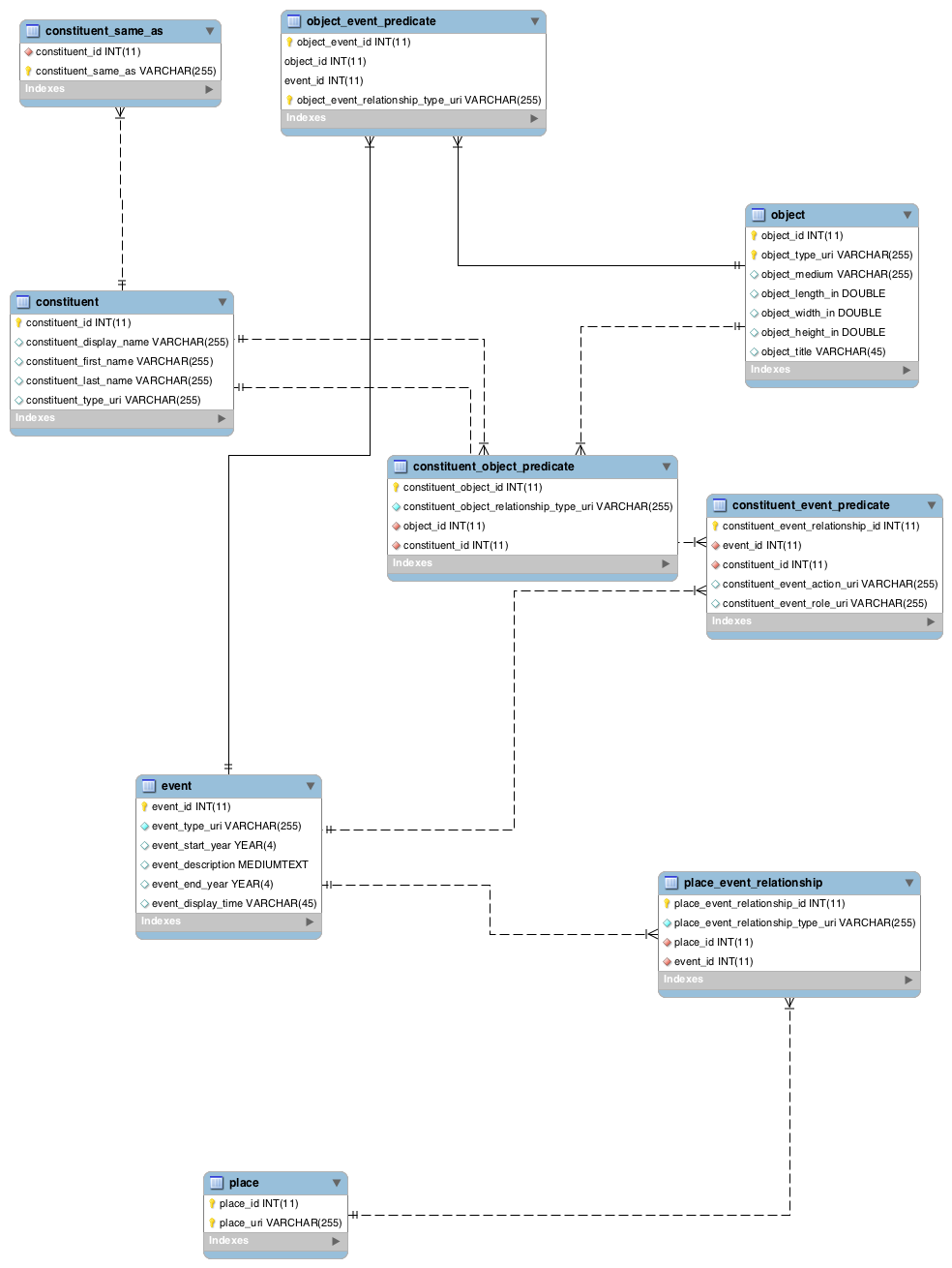
Prof. Miller gave my Program for Cultural Heritage class read-only access to the NYPL’s archives database. Looking at the way this data is structured, particularly access terms for constituents, is helpful in thinking about tabular structure for the Whitney’s linked data.
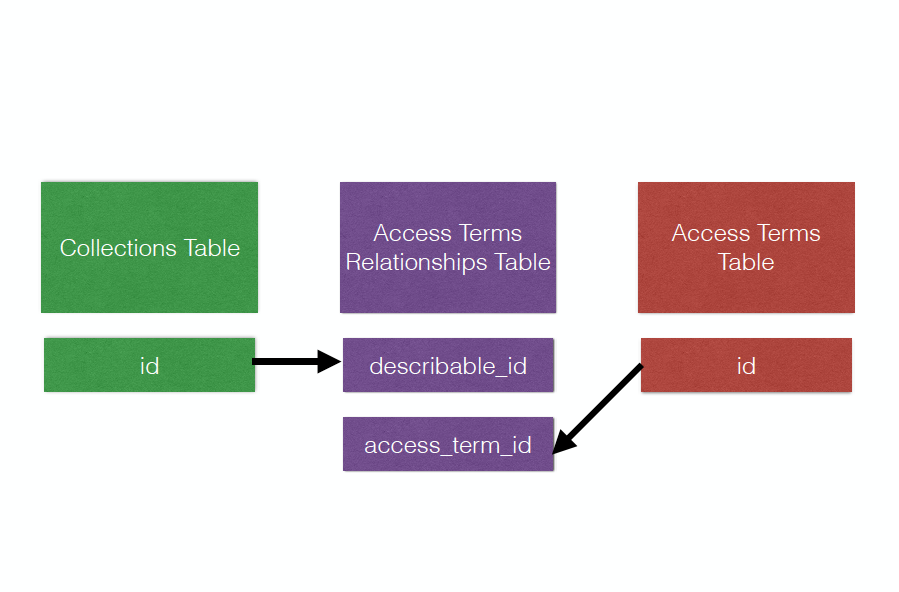
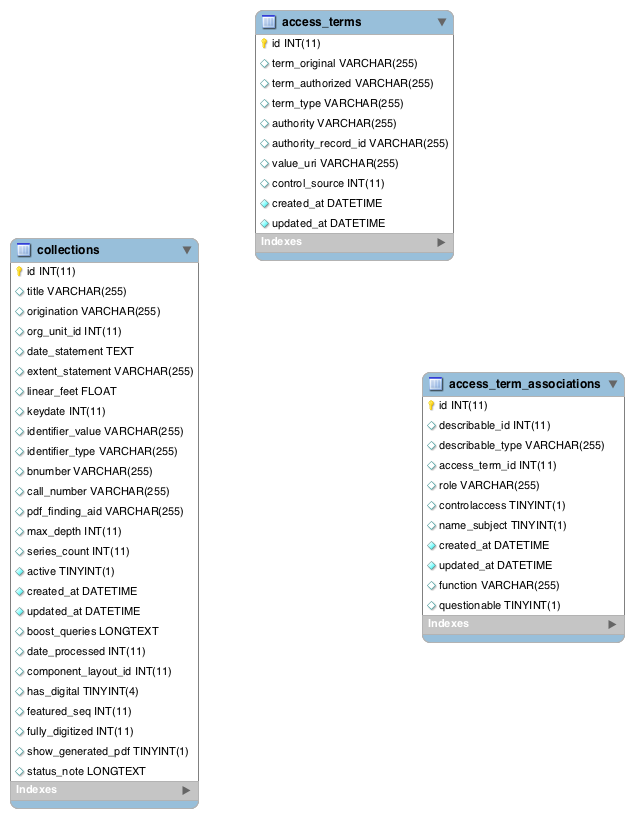
There are three tables in the NYPL Archives schema, `collections`, `access_terms`, and `access_term_associations`
The `access_term_associations` table is used to link the individual archival collections, store in the `collections` tables, to names of constituents, which are stored in the `access_terms` table:
This structure allows the NYPL to generate some interesting interactive interfaces: http://archives.nypl.org/tools
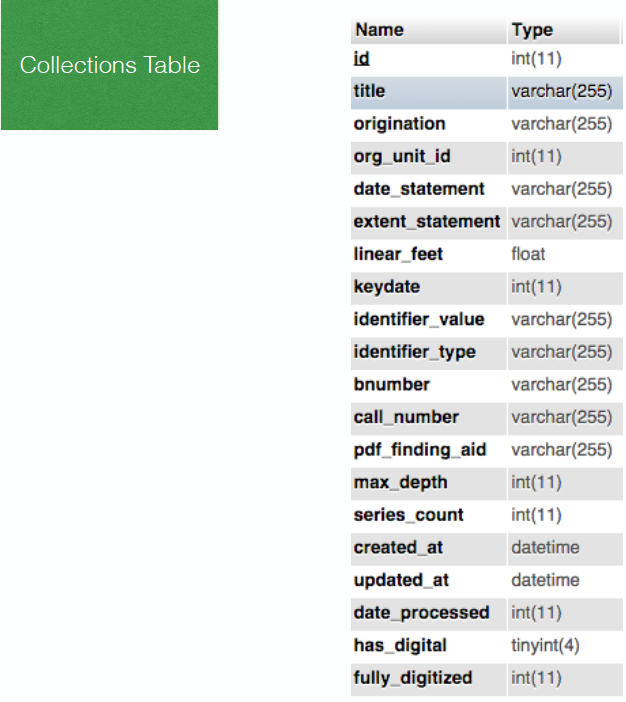

An archival collection from this database represented in JSON:
{
“id” : 1,
“title” : “Thomas Addis Emmet collection”,
“origination” : “Emmet, Thomas Addis,\n 1828-1919”,
“org_unit_id” : 1,
“date_statement” : “1483-1876 [bulk 1700-1800]”,
“extent_statement” : “30.83 linear feet; 108 boxes, 21 volumes”,
“linear_feet” : 30.83,
“keydate” : 1483,
“identifier_value” : “927”,
“identifier_type” : “local_mss”,
“bnumber” : null,
“call_number” : “MssCol 927”,
“pdf_finding_aid” : “”,
“max_depth” : 3,
“series_count” : 28,
“active” : 1,
“created_at” : “2013-01-08 20:52:54”,
“updated_at” : “2015-11-05 03:03:37”,
“boost_queries” : “[\”emmet\”]”,
“date_processed” : null,
“component_layout_id” : 2,
“has_digital” : 1,
“featured_seq” : null,
“fully_digitized” : 1,
“show_generated_pdf” : 0,
“status_note” : null
},
These archival materials don’t have URIs associated with them directly, presumably since they are organized at collection level.
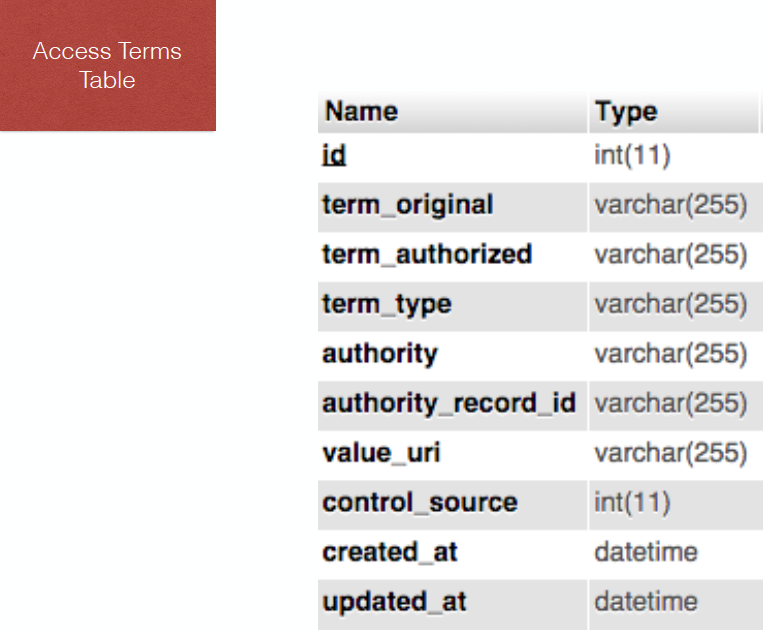
A constituent or concept related to this collection, including a link to a name authority record:
{
“id” : 3004,
“term_original” : “Legislators–United States”,
“term_authorized” : null,
“term_type” : “topic”,
“authority” : “lcsh”,
“authority_record_id” : null,
“value_uri” : “http://id.loc.gov/authorities/subjects/sh85075851”,
“control_source” : null,
“created_at” : “2013-01-08 21:01:45”,
“updated_at” : “2013-01-08 21:01:45”
},
The access terms association that shows the relationship between the collection and concepts/people related to it.
{
“id” : 7246,
“describable_id” : 1,
“describable_type” : “Collection”,
“access_term_id” : 3004,
“role” : null,
“controlaccess” : 1,
“name_subject” : 0,
“created_at” : “2013-01-08 21:01:45”,
“updated_at” : “2013-01-08 21:01:45”,
“function” : null,
“questionable” : 0
},
Because there may be many terms associated with each collection, and since any given term may apply to multiple collections, the access terms association table exists to represent this many-to-many relationship.
For the Whitney’s data, event table(s) could serve a similar role as the access terms association table for the NYPL, connecting constituents and objects as well as places and thesaurus terms.
While non-relational databases are the standard for storing linked data, at the same time, since linked data is all about relationships, it would seem reasonable that it could be used to represent linked data relationships as well. There is still the issue of hosting, however, which is presumably where the use of a triple store would be needed.
This site (https://sites.tufts.edu/liam/) gives a great overview of some methodologies of implementing linked data in archival settings, and also argues in favor of using a relational database as the basis for generating triples.
The article mentions D2RQ, a tool for hosting relational data I explored briefly and unsuccessfully tried to install earlier in the semester. I’m not sure if I would have the technical ability to install it, but if IT at the Whitney could implement it like they did Joshua’s PHP server, I could develop a MySQL database and host it on this server, solving the triple store issue and having a SPARQL endpoint available as well.
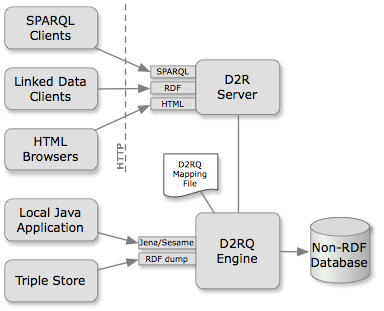
The article also mentions a project called ReLoad, which seems to involve URIs and a SPARQL endpoint generated by/stored in xDAMS. The URI links for this project seem to be dead, however, and I’m somewhat unclear about how everything within the project is structured.
Experimenting with Databases
I ended up creating a test MySQL database to input. I uploaded a SQL file for this database to GitHub.