Data Work
I’m still at it with the tabular data work. I spent the morning working alternately with MySQL Workbench and OpenRefine, trying to refresh my knowledge of SQL and regular expressions in the process.
The amount of time I’ve been spending on this normalization work is making me wonder whether I should just try feeding the data directly from TMS into Karma. Throughout this project, I feel like I’ve tended to get distracted and waste time whenever databases are concerned.
Realistically, if the Whitney wants to eventually publish all of its collection data as LOD, the museum is probably not going to have the resources to go through all this normalization work for every record. Importing data directly from TMS to Karma would allow the Whitney to publish at least some bare-bones linked data on Github (a la the Getty) with relatively little time and resources expended.
This is a super-simplified example of how provenance could be modeled with CIDOC used data straight from TMS: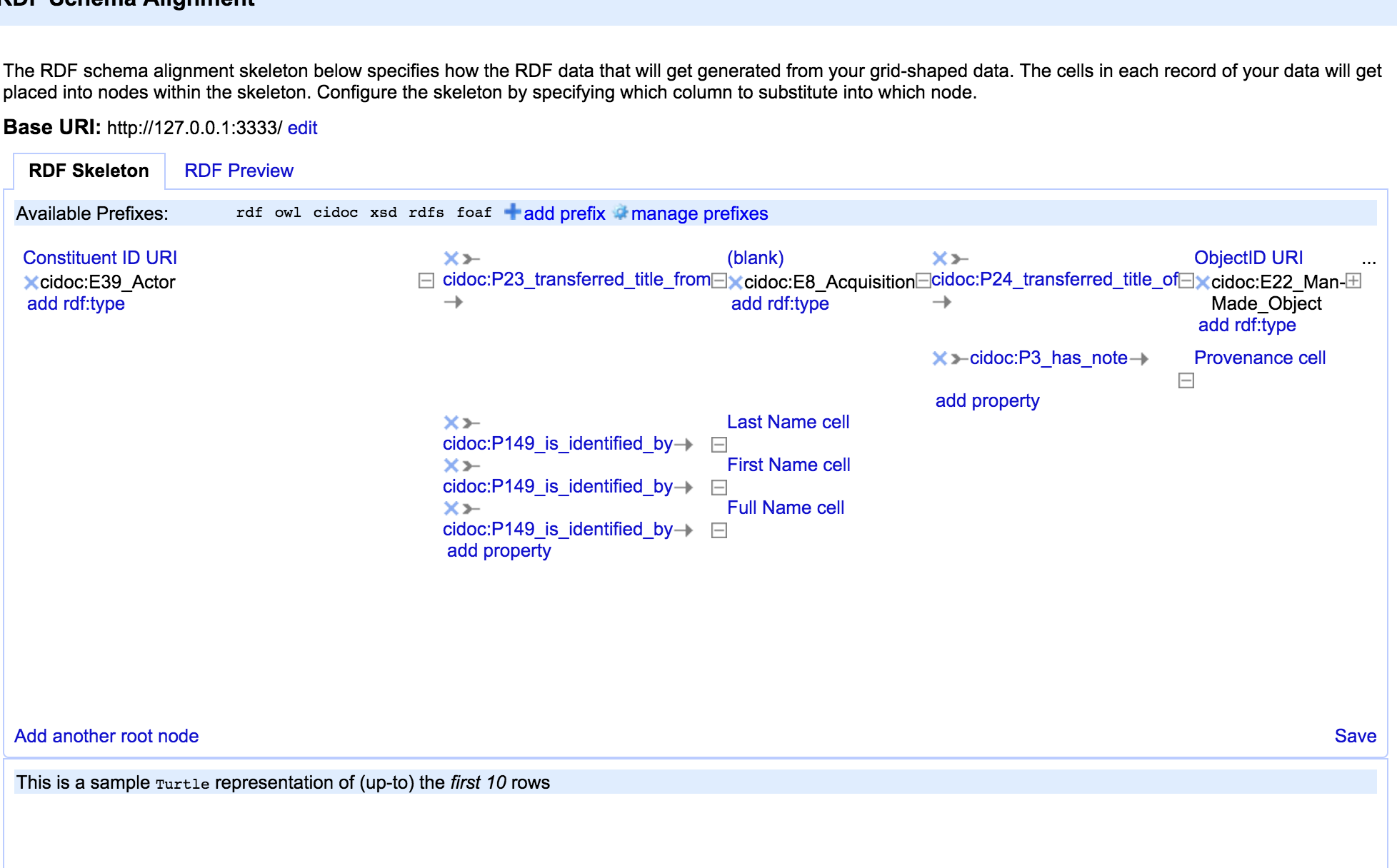
Reconciliation
As per this listserv post (http://si-listserv.si.edu/cgi-bin/wa?A3=ind1509&L=TMSUSERS&E=quoted-printable&P=1667361&B=–001a113a6aaa3737ea051eee5830&T=text%2Fhtml;%20charset=UTF-8), I am going to try Reconcile-CSV (http://okfnlabs.org/reconcile-csv/), an OpenRefine plugin, as the RDF plugin for OpenRefine seems to have issues with some reconciliation services.
Rebuilding the Getty Provenance Index as Linked Data
http://backup.cni.org/topics/digital-humanities/rebuilding-the-getty-provenance-index-as-linked-data
https://www.youtube.com/watch?v=1HRbP4zjqPM
The Getty have tried both Karma and 3M, but have not settled on a favorite solution.
Joshua Gomez from the Getty likes Karma because of its ability to generate graphs
Screenshots of the Getty Model:
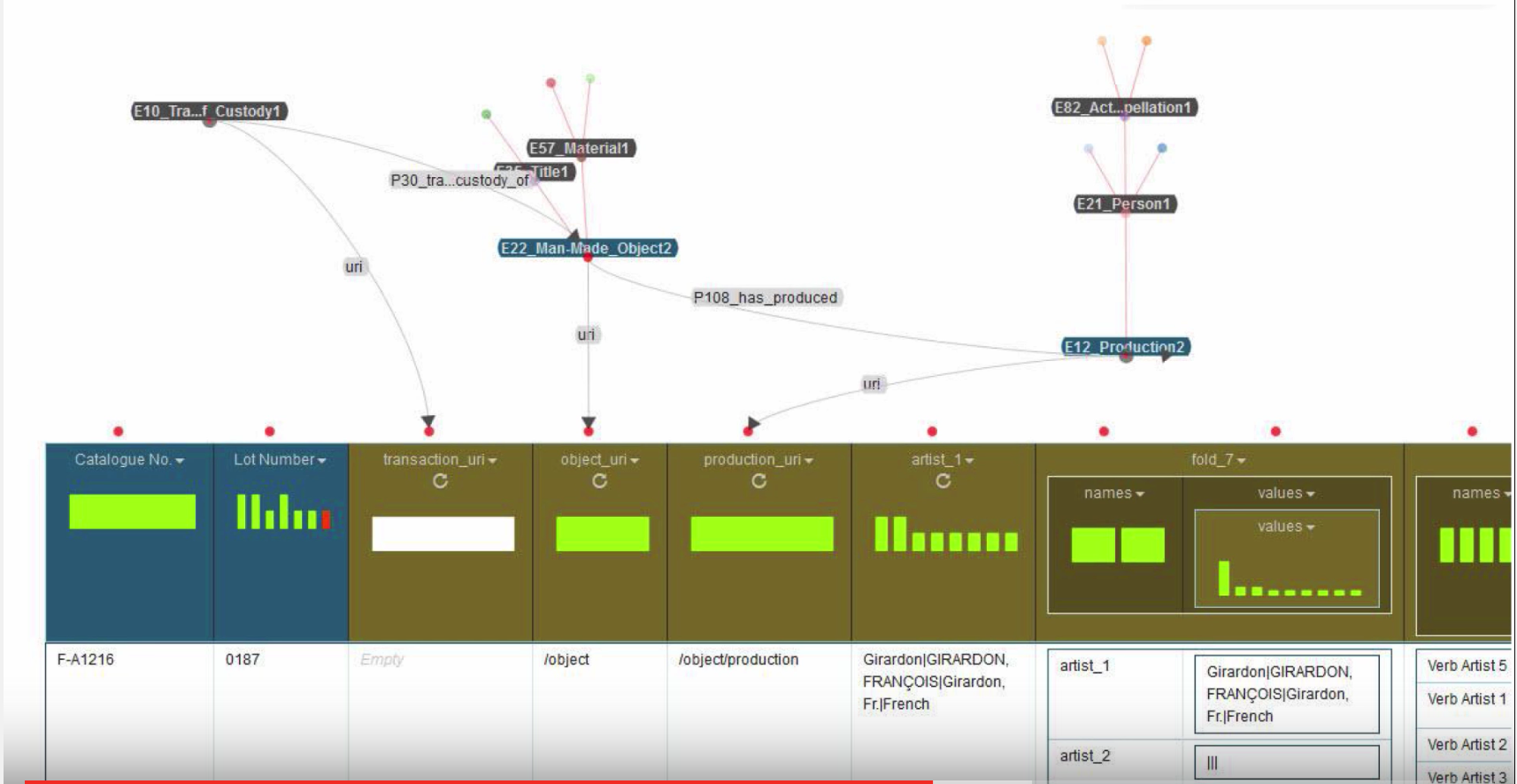
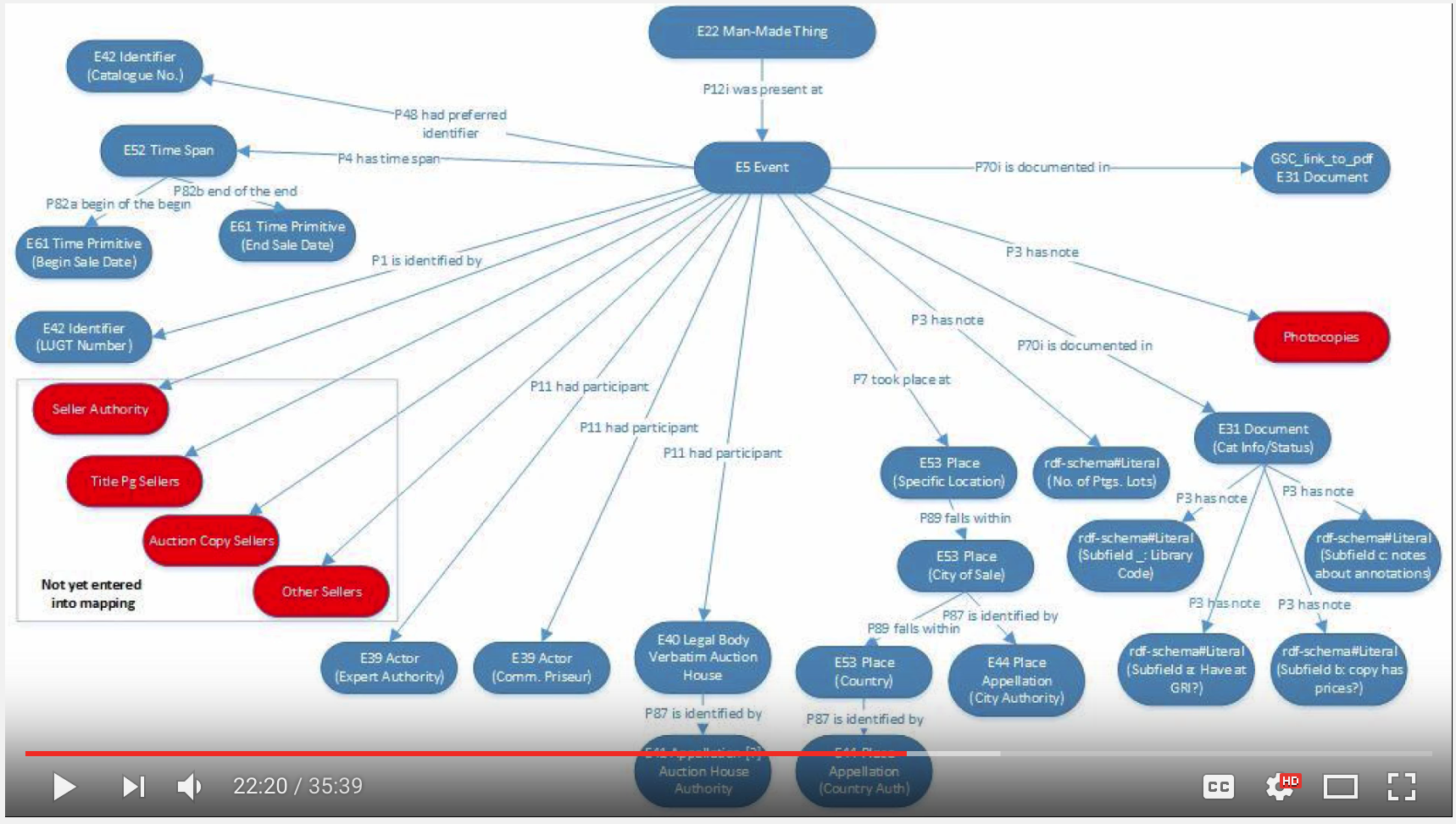
Interesting that the Getty uses E10 Transfer of Custody instead of E8 Acquisition. I talked to Prof. Pattuelli about this issue this past week, as she suggested using E10. CIDOC says:
“The interpretation of the museum notion of “accession” differs between institutions. The CRM therefore models legal ownership and physical custody separately. Institutions will then model their specific notions of accession and deaccession as combinations of these.”
“Ιt may also describe events where a collector appropriates legal title, for example by annexation or field collection. The interpretation of the museum notion of “accession” differs between institutions. The CRM therefore models legal ownership (E8 Acquisition) and physical custody (E10 Transfer of Custody) separately. Institutions will then model their specific notions of accession and deaccession as combinations of these.”
Since provenance is, by definition, “a record of ownership of a work of art or an antique, used as a guide to authenticity or quality.”, I feel that E8 is the more appropriate CIDOC entity class for this, as it specifically records legal ownership as opposed to physical possession. E10, could, however, also be included in a linked data model. This would probably require data from the Accession Sheet field in TMS.
According to Gomez, CIDOC’s recent expansion of purchase-based entity classes was precipitated by the Getty project.
Due to the slowness of triple-stores, Gomez decided to put the Getty’s LOD in Elasticsearch (https://github.com/elastic/elasticsearch). This allows for REST API searching. Less complicated than a SPARQL endpoint.
Gomez mentions a data ingest platform called Arches (http://archesproject.org/) being developed by the Getty Conservation Institute (http://www.getty.edu/conservation/our_projects/field_projects/arches/)
Arches is built to catalog immovable cultural heritage (ie sites, buildings)
Data Work Continued
I started playing around with the Gift constituents CSV file in Karma, but realized I need to do more OpenRefine work before import
I switched over to LODRefine from standard OpenRefine, as its capabilities seem to be slightly beyond the OpenRefine RDF plugin
After some exploration, plain OpenRefine works best. LODRefine is heavily reliant on deprecated services like Freebase, unfortunately.
OpenRefine’s reconciliation service makes querying for external URIs with Python pretty much unnecessary.
This guide (https://data-lessons.github.io/library-openrefine/05-advance-functions/) details how to split those reconciled URIs into their own columns.
I did the Gift Constituents list as a sample, and exported it as RDF/XML to see what intake into Karma would be like. I think uploading as tabular data might work better for Karma.