Getty’s Knoedler Dataset
I’m thinking it might be interesting to compare the Getty’s Knoedler dataset with the Whitney’s. While none of the Whitney Founding Collection objects came from Knoedler, they were an influential 19th-early 20th century gallery, and sold to Gertrude Vanderbilt Whitney’s father/grandfather(?) Cornelius (http://www.artnews.com/2016/04/25/the-big-fake-behind-the-scenes-of-knoedler-gallerys-downfall/), among other influential robber barons of the time. I imagine there might be some overlap between artists or collectors in the two datasets, if nothing else.
Strangely, a cursory search of TMS reveals that Knoedler Gallery has only one related object in the database (a Jasper Johns artist book, ID 84.52)
The Getty’s provenance resources also skew heavily towards pre-20th century sources (presumably due to copyright issues) and records from European auction houses.
The Knoedler sales books do encompass the years the Whitney Founding Collection was amassed, as well as the decades before and after, so hopefully the Getty’s Knoedler dataset has some kind of linkage with the Whitney’s.
As the readme in the Getty’s Github repository notes, the Carnegie Museum also has their collection data available in both CSV and JSON format:
https://github.com/cmoa/collection
To go about connecting the Whitney’s dataset to the Getty’s and/or Carnegie’s, I would have to use a similar to what Hannah and Molly did for their Program for Cultural Heritage project:
https://github.com/MollieEcheverria/CH-LJ/blob/master/README.txt
I might need to query for URIs for the Getty/Carnegie names first.
OpenRefine
Before I get into external datasets, I am going to start working with the Whitney’s data using OpenRefine.
I’m using this book as a reference:
Verborgh, R., De Wilde, M., & Sawant, A. (2013). Using OpenRefine : The Essential OpenRefine Guide That Takes You From Data Analysis and Error Fixing to Linking Your Dataset to the Web.Birmingham, England: Packt Publishing. Retrieved fromhttp://search.ebscohost.com.ezproxy.pratt.edu:2048/login.aspx?direct=true&db=nlebk&AN=639455&site=ehost-live&ebv=EK&ppid=Page-__-20
A preliminary look at the RDF Refine extension for OpenRefine (http://refine.deri.ie/) is promising. I tried plugging in the BloodyBite CIDOC mapping namespace I think I mentioned previously (http://bloody-byte.net/rdf/cidoc-crm/core_5.0.1#) to get CIDOC classes/properties:
Sidenote: this namespace lookup resource looks helpful as well:
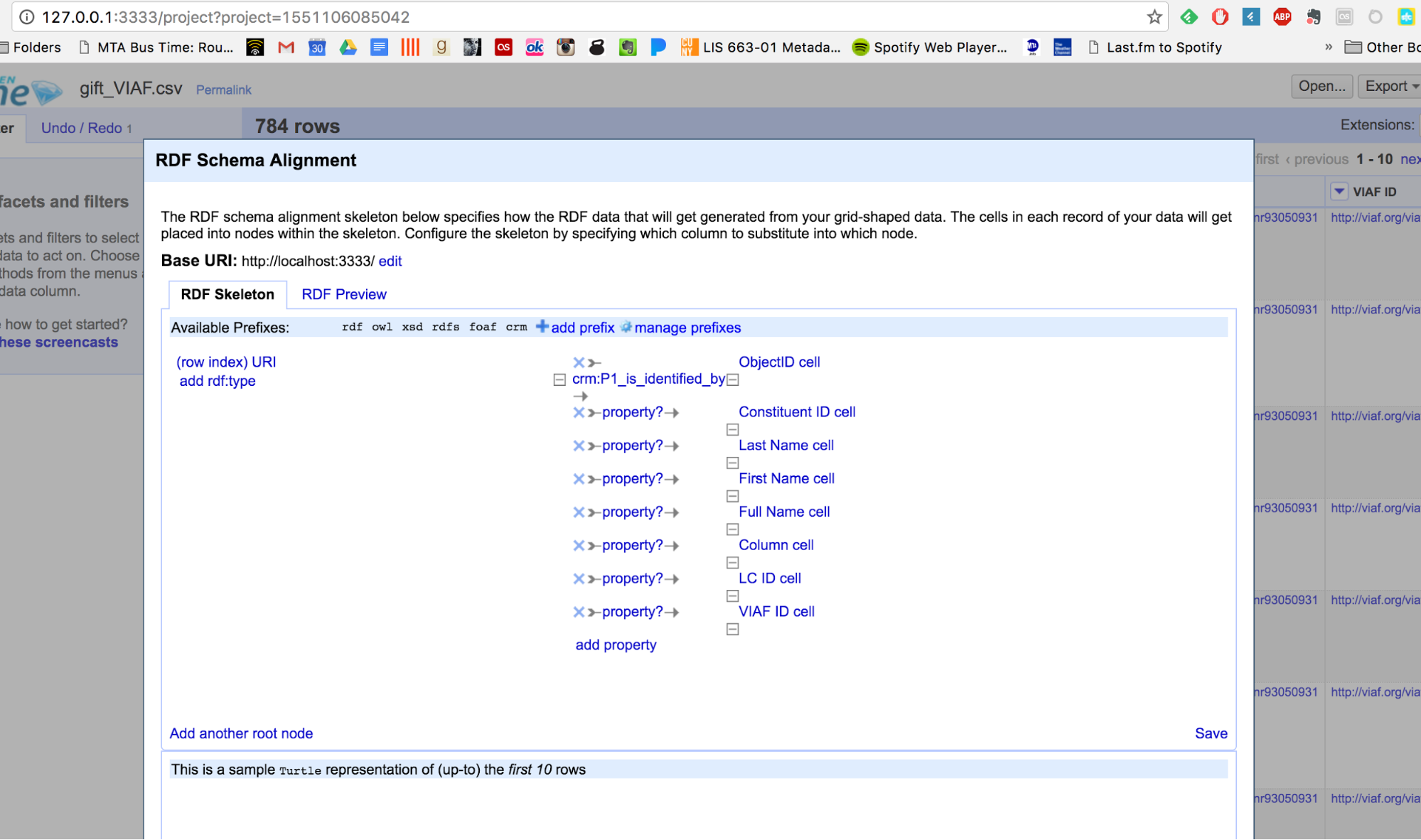
The Erlangen OWL mapping used by the British Museum works well too:
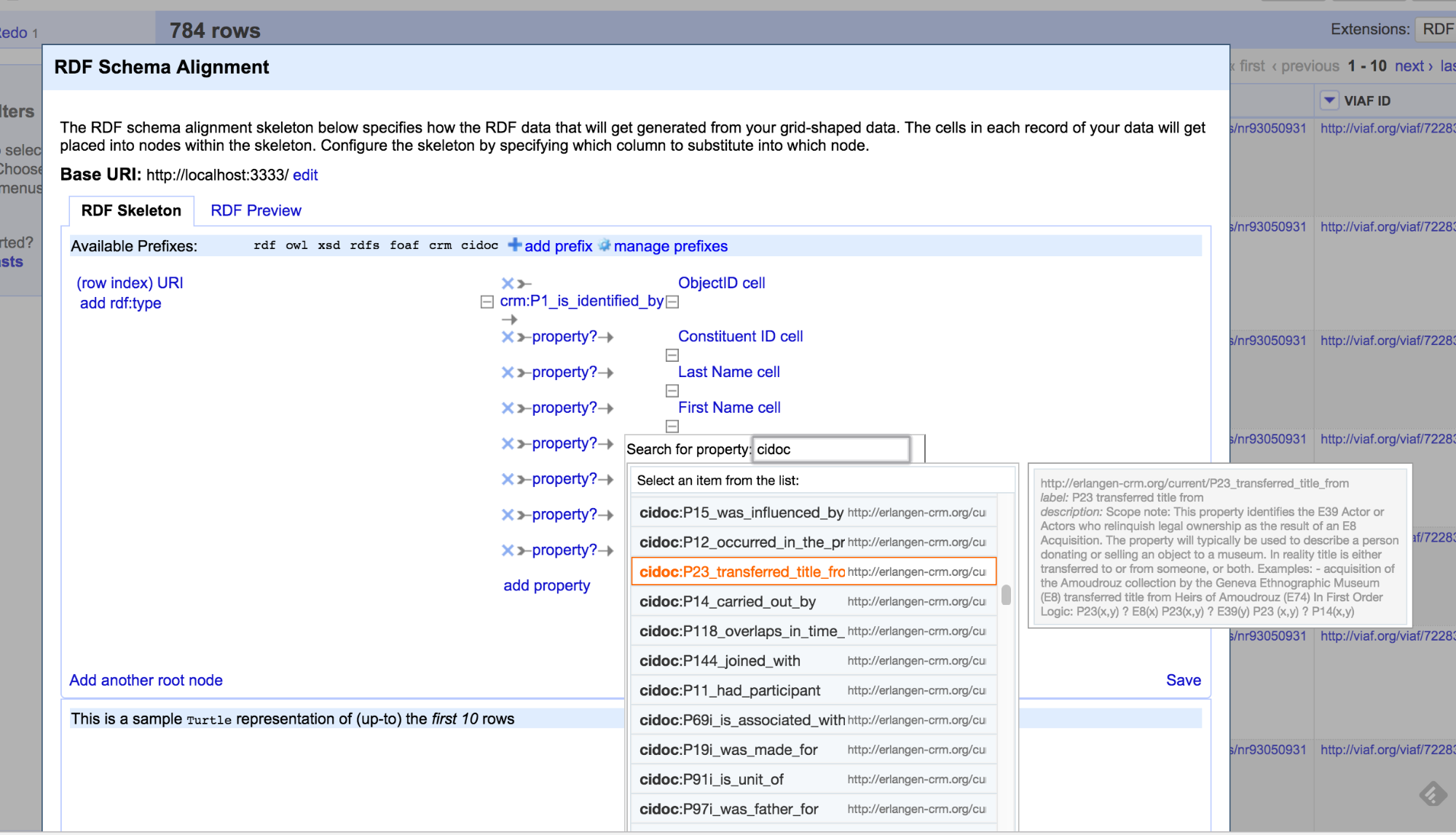
Since I have all the columns in my Google Sheets aligned with CIDOC properties, the RDF schema alignment process should hopefully be pretty easy.
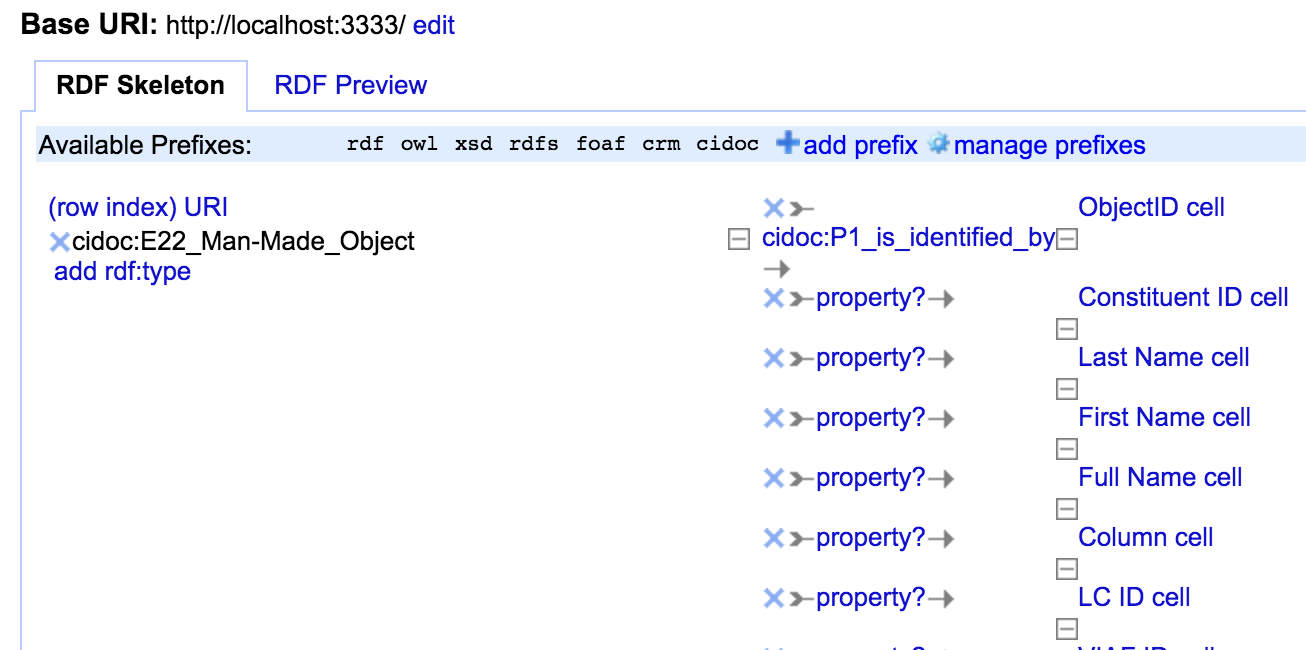
This plugin lets you identify entity nodes as well, so I could probably just simplify things and recombine all my separate sheets into one CSV file rather than having one sheet per entity:
https://en.wikipedia.org/wiki/Node_(computer_science)
https://en.wikipedia.org/wiki/Linked_data_structure
OpenRefine also does Wikidata reconciliation!
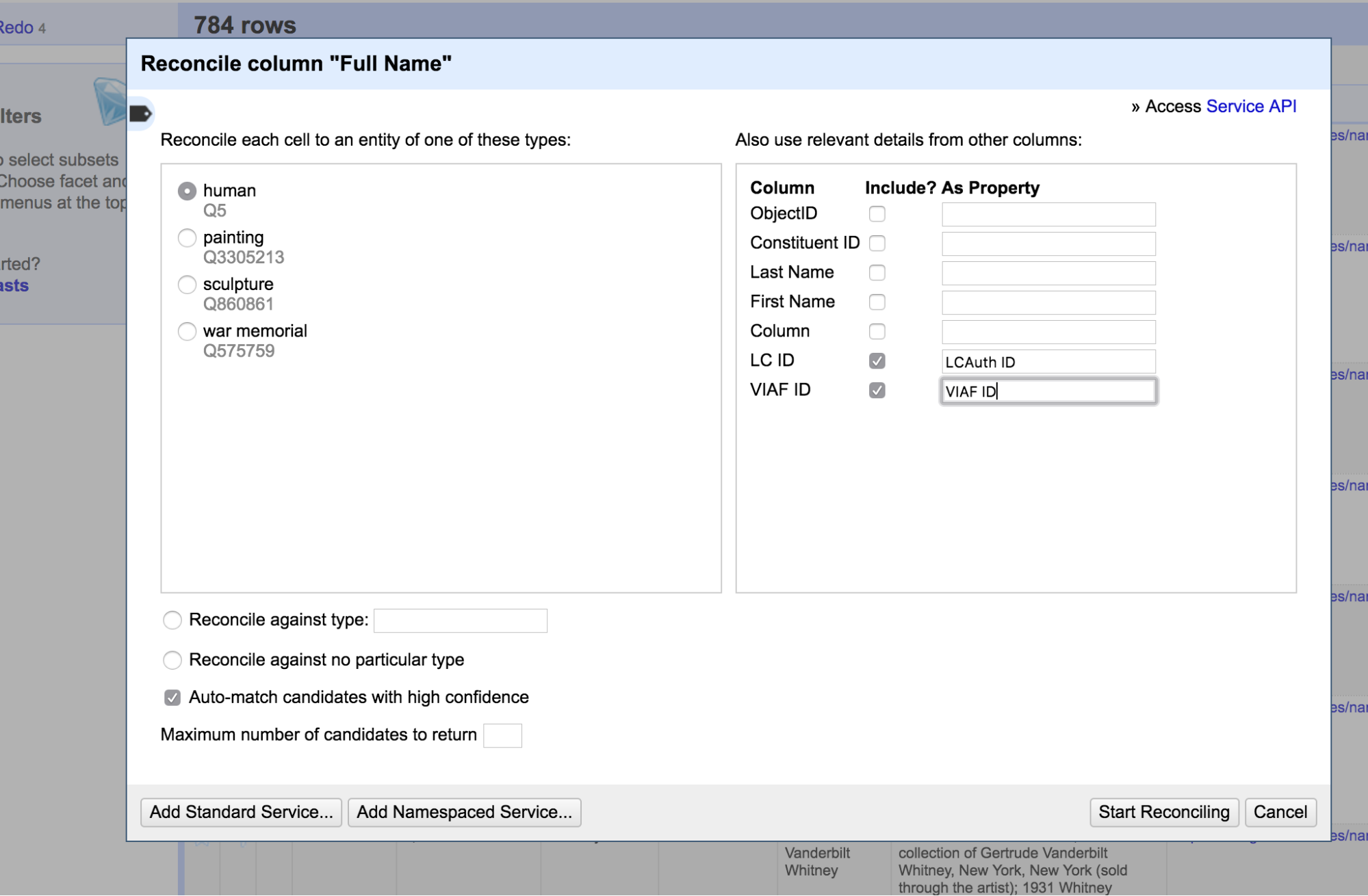
You can reconcile against SPARQL endpoints too! (https://github.com/OpenRefine/OpenRefine/wiki/Reconcilable-Data-Sources)
Adding name reconciliation sources: http://iphylo.blogspot.com/2012/02/using-google-refine-and-taxonomic.html
You can even generate RDF/XML or Turtle files from OpenRefine (no JSON-LD, sadly)
Publishing these RDF files on GitHub might be a simple preliminary way to share the Whitney’s data
Or, I could use something like this (https://github.com/semsol/arc2/wiki), though that might be again getting hung up on publication/databases.
It’s a bit tricky in practice:
In working with OpenRefine, I realize all my spreadsheets are a little out of control in terms of granularity.
Revised Project Plan
Recombine spreadsheets into three main sheets (Constituent, Object, Event)
Do name reconciliation/RDF schema layout stuff in OpenRefine
Feed sheet into Gephi and make visualization.
Also spit out some RDF/XML files and make into an N-Triple/JSON-LD
http://rdf-translator.appspot.com/
Clean and reconcile Getty/Carnegie data with OpenRefine too and try to make some connections.
Make a Gephi visualization mapping the connections