Drawings of the Florentine Painters Project and Whitney Model
After reading more on Drawings of the Florentine Painters, I think the project offers a very concise model for how to proceed with the Whitney’s linked data in the spring.
While I was originally thinking to just use CIDOC entities and properties plus Art and Architecture Thesaurus controlled terms, I can see now that incorporating ULAN/VIAF authority files into the Whitney model would be beneficial, particularly given that CIDOC only has a namespace page for its properties rather than URIs.
After querying Wikidata for my project in Programming for Cultural Heritage, I don’t think it would be a good name authority source for the Whitney. During my early exploration of
Acquisition-related names related to the Whitney Founding, I found that even some of the most obscure early 20th century art dealers had VIAF or LCSH files, whereas I doubt Wikidata would have much information on these constituents.
Geonames would also be a good source for place names.
Rough Outline of Work for Spring
My work in Spring will be roughly structured around how Alex Provo et al. have described their process in their soon-to-be-published write-up on the Drawings of the Florentine Painters project.
Data Preparation: Now – Jan 21st, 2017
I first need to combine all of my and Joshua’s data into three main CSV files, constituents, objects, and events. This can be done with Google Sheets.
I might also need to query TMS for some additional constituent data.
Data Processing: Jan 21st – Feb 4th, 2017
I would then use OpenRefine and possibly Python to handle any discrepancies in the data (splitting, cleaning, merging, etc).
I could either keep this data in CSV files or import it into a MySQL database. A relational database might be easier to manage and append, and might also be more useful for representing relationships, but could take time to build.
Data Modeling Refinement/Extension: Feb 4th – 11th, 2017
I might refine the Whitney model based on the data at this point. The Florentine Renaissance Painters project experimented with incorporating equivalent properties from other ontologies like Dublin Core along with CIDOC, although this idea was ultimately scrapped. I’m taking Metadata: Description and Access in the Spring, so I may have a better sense of whether to include other schemas and what other schemas to incorporate by February.
Defining the Conceptual Model in 3M: Feb 11th – March 4th, 2017
The Florentine Renaissance Painters project used two applications to map its tabular data onto CIDOC: Mapping Memory Manager (3M) and Karma
3M (http://139.91.183.3/3M/FirstPage):
3M (which unfortunately has kind of a buggy website), is a web-based tool for managing mapping definition files.
This document (http://83.212.168.219/DariahCrete/sites/default/files/mapping_manual_version_4g.pdf) has more details on how to use 3M.
The aforementioned PDF also contains mentions this hierarchical representation of CIDOC in Standford’s Web Protegé, which is a useful representation of CIDOC classes ranked from general to specific: http://webprotege.stanford.edu/#Edit:projectId=6fe69ce8-94b9-4624-bfe6-43af7c6d0fe3
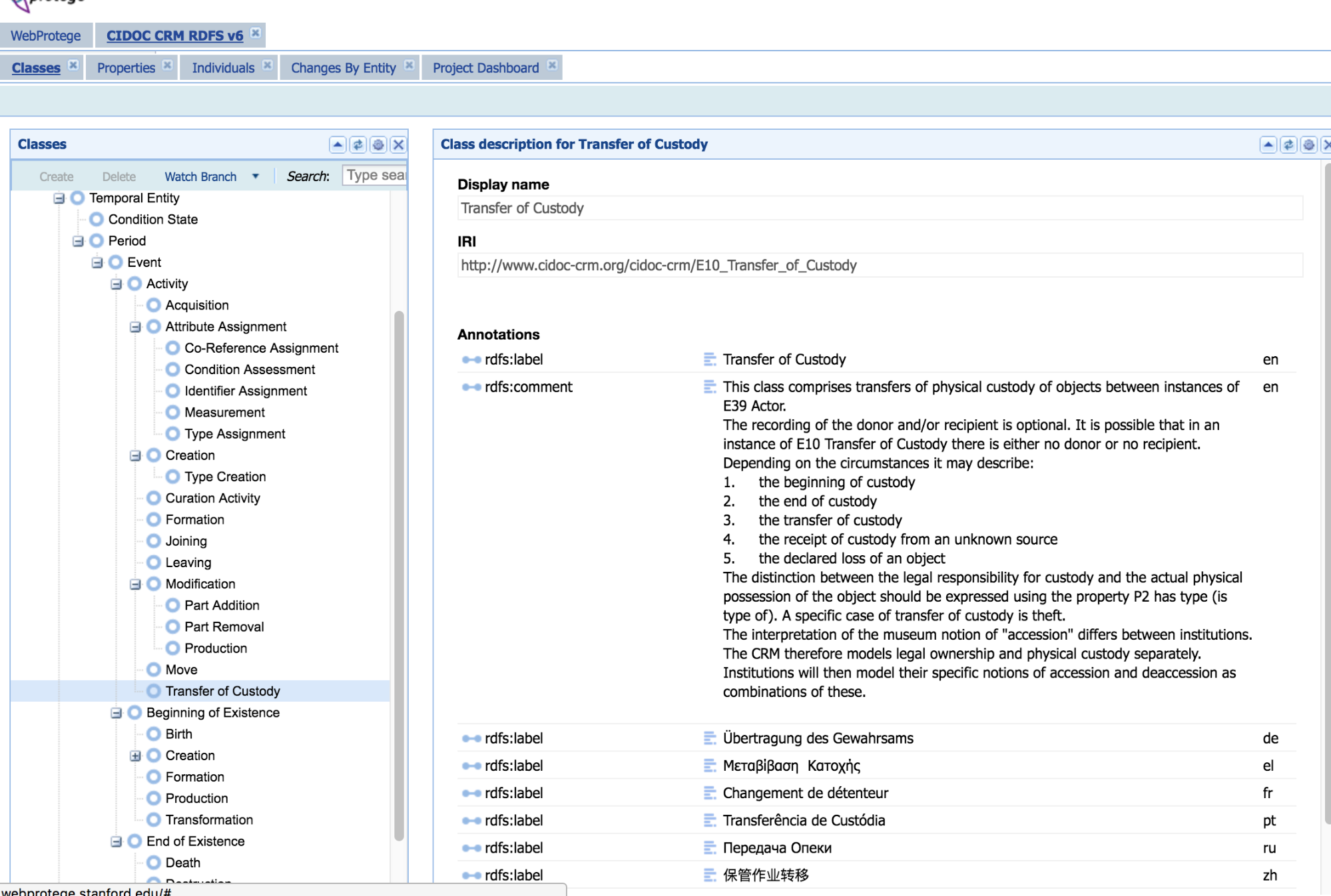
3M is built specifically for CIDOC mappings. As my model for the Whitney is based on CIDOC, I can use the site to map the Whitney’s linked data.
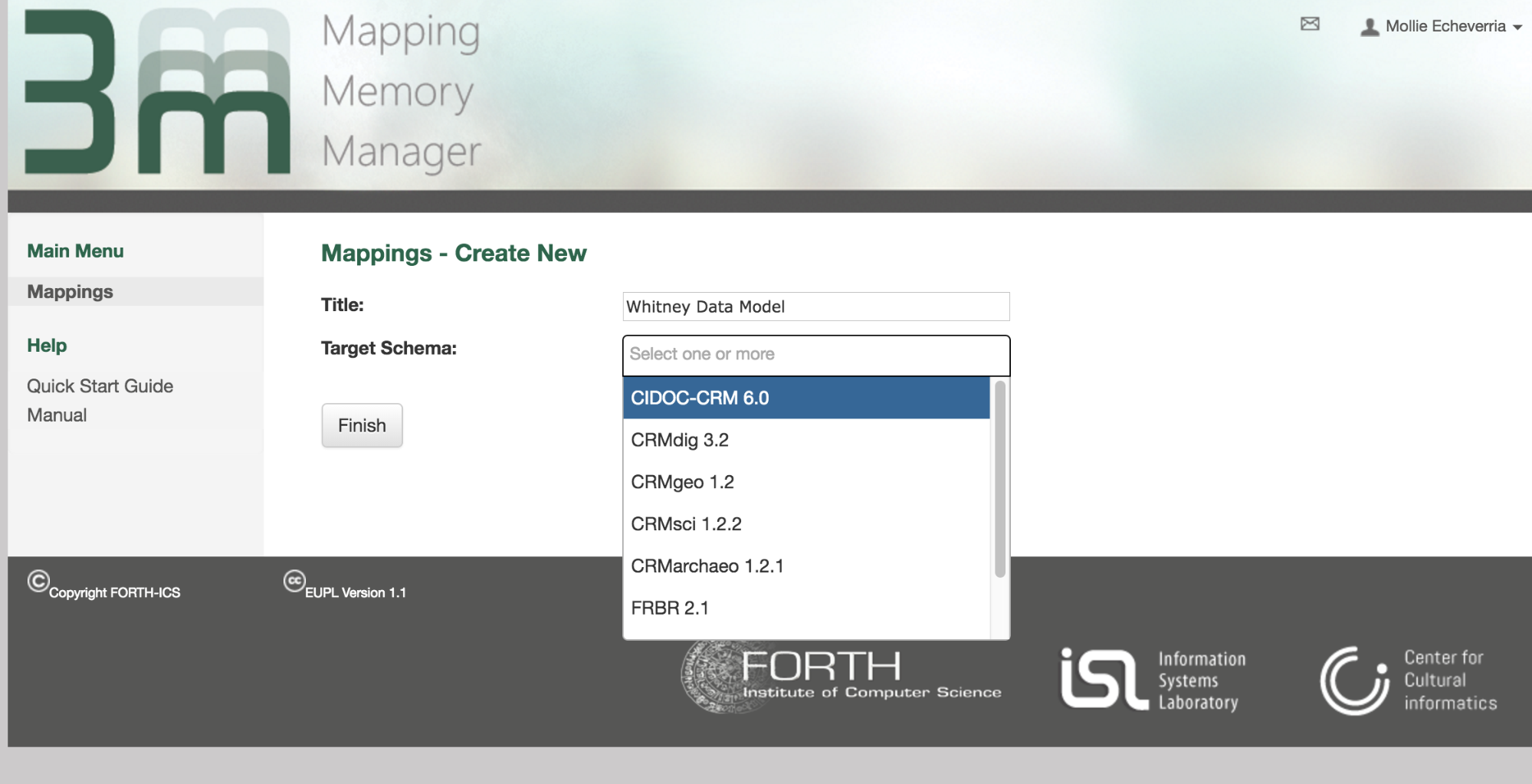
3M has over 500 different mappings hosted at present, primarily CIDOC-based. These include mappings of LIDO and Dublin Core onto CIDOC, models based on internal relational database content, and even what looks like someone’s attempt to map the TMS eMuseums module:
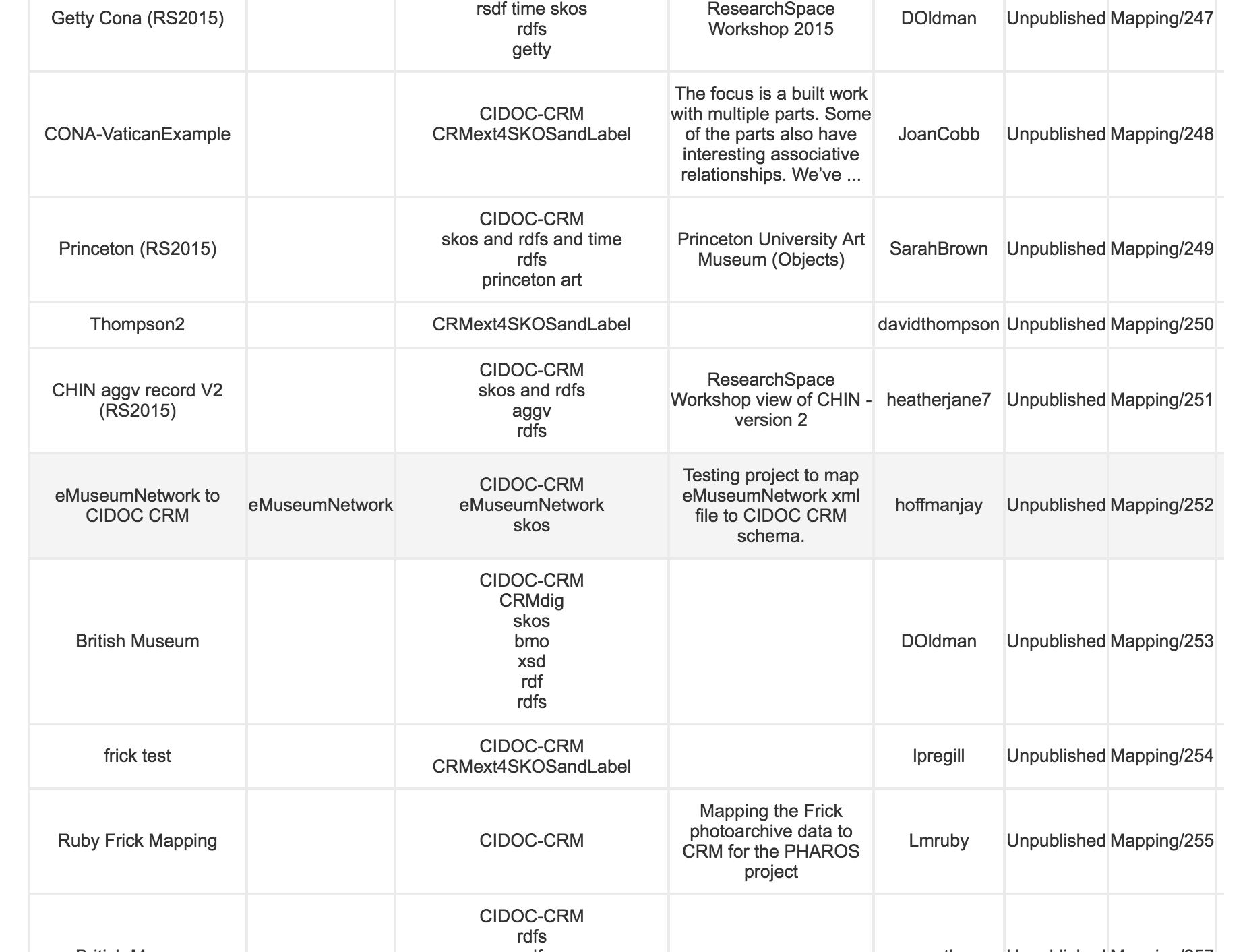
Schemas are uploaded as XML. You can also export other people’s data mappings, see detailed comparisons of different mappings of the same source schema, and view detailed analysis of your schema:
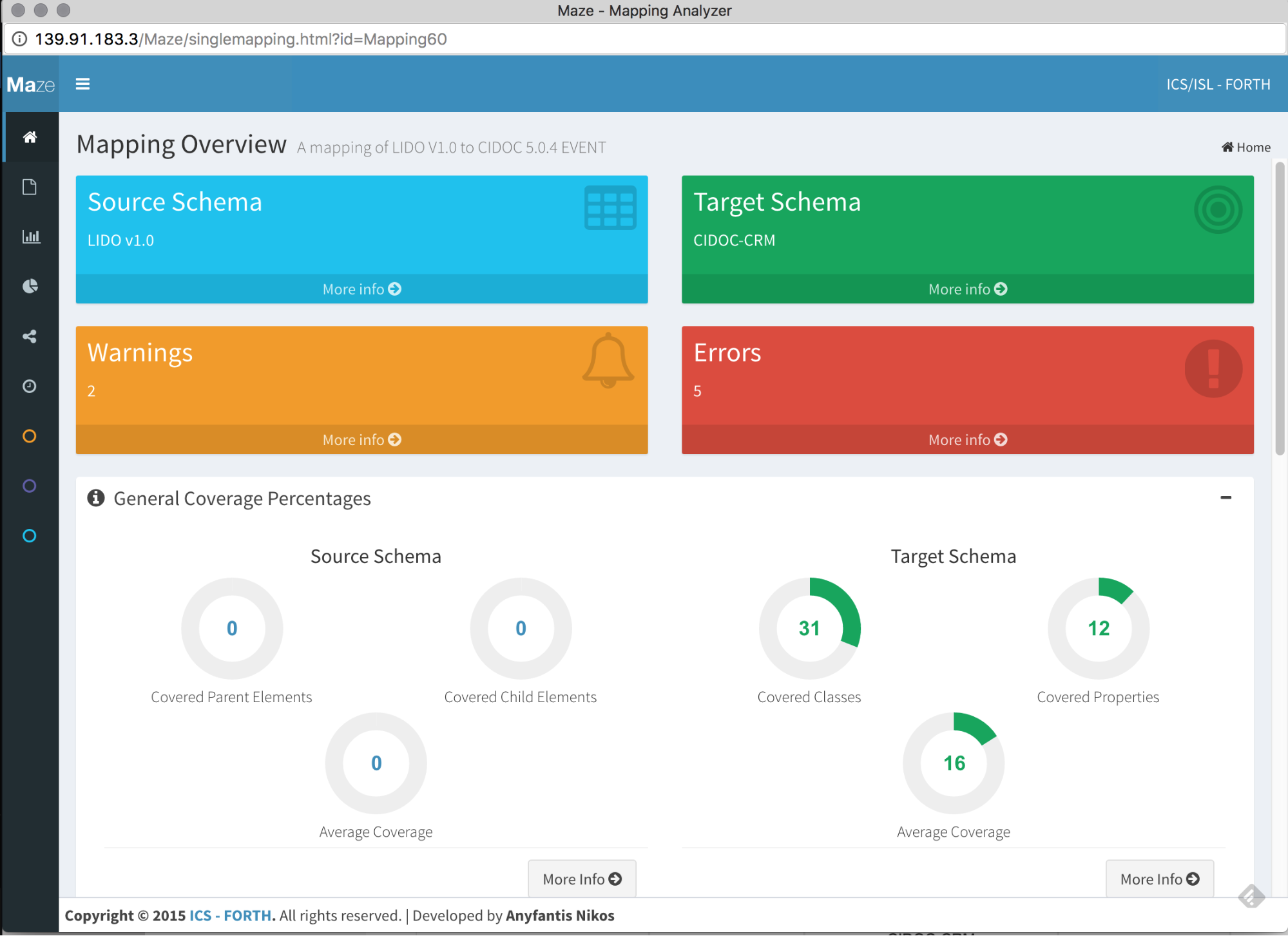
To plug in the Whitney’s data, I would first need a source schema in XML form. This would be sourced from the TMS fields in whatever tabular data I have. I’m still a little unclear on how to do this; Alexandra apparently used a Python script to convert the column names in her tabular data to XML. 3M has an XML schema called X3ML that it provides as template for source schemas, so I could also probably just manually plug fields into this template. The documentation for 3M also explains how to use joins to convert relational database source data to a usable XML source schema.
3M also requires a URI policy generator XML file, which it uses to create URIs associated with whatever domain the source schema is hosted on (/whitney/collection/object/23928, etc).
Once these two files are uploaded to 3M, I can use the site’s interface to associate each TMS field with a CIDOC class or property. 3M can also validate your mapping and suggest other class and entity mappings.
The final mapping (or Target Record) can then be exported from 3M as RDF/XML, N-Triples, or Turtle.
Mapping Whitney TMS Data to Classes and Properties: March 4th – 25th, 2017
Karma (http://usc-isi-i2.github.io/karma/)
Karma is a data integration tool that can be used for database data, spreadsheets, XML, and JSON. Karma automates the process of adding URIs to this data and mapping it to an ontology.
This document (http://www.isi.edu/~szekely/contents/papers/2013/eswc-2013-saam.pdf) details its use in greater detail.
I would start by preparing the Whitney’s tabular data for import into Karma, either directly from a CSV file, or from a SQL database if I choose to use one. Depending on what storage format I choose, I would either concatenate columns in MySQL or use OpenRefine.
Karma is a desktop app that runs something like MySQL Workbench. You work with and manage data locally, but this can later be hosted on an external server.
Karma can also run using data from a hosted SQL database. If I choose to store my initial data in a SQL database, I could opt to host this on the internal Whitney server Joshua used this past year and access Karma through there.
I would then use Karma to map the various columns of data onto classes from the CIDOC mapping I refined in 3M.
Data Enrichment: March 25th – April 15th, 2017
Karma also integrates the ability to link data to external resources.
VIAF/LCSH/ULAN: For Acquisition-related constituents. Joshua already used ULAN for Object-related constituents, but it might be worth enriching his data with VIAF/LCSH data as well.
Geonames: For places related to events/constituents
DBpedia/Wikidata: I don’t know how many of the Whitney’s non-artist constituents (in particular Acquisition-related constituents) would have records on these sites, but they might be worth investigating if time permits.
Data from Other Museums (The Smithsonian, British Museum, etc): This actually might be the most important enrichment data to include. One of the main goals of implementing linked open data at the Whitney would be to enable the sharing of resources with other art-related cultural institutions, so this integration is key.
Data Publishing: April 15th – 29th, 2017
Once all the data is prepared, it can then be hosted in some kind of graph database.
Drawings of the Florentine Painters is using Metaphacts (http://www.metaphacts.com/), which seems like an attractive solution.
This would either be hosted on the Whitney server, or possibly on the server of whatever company I use.
Visualization(s) and Incorporating Images: April 29th – May 13th, 2017
Time permitting, I will create some kind of visualization project with the Whitney’s data using Gephi/Tableau.
I could also try to incorporate image content from TMS/the main Whitney Collection page in some way.